Map 和 Collection
首先你的熟悉这两个接口的常用实现类结构, 2张图补全知识点 (用过 IntellijIDEA 的应该知道如何生成下面的图 ):
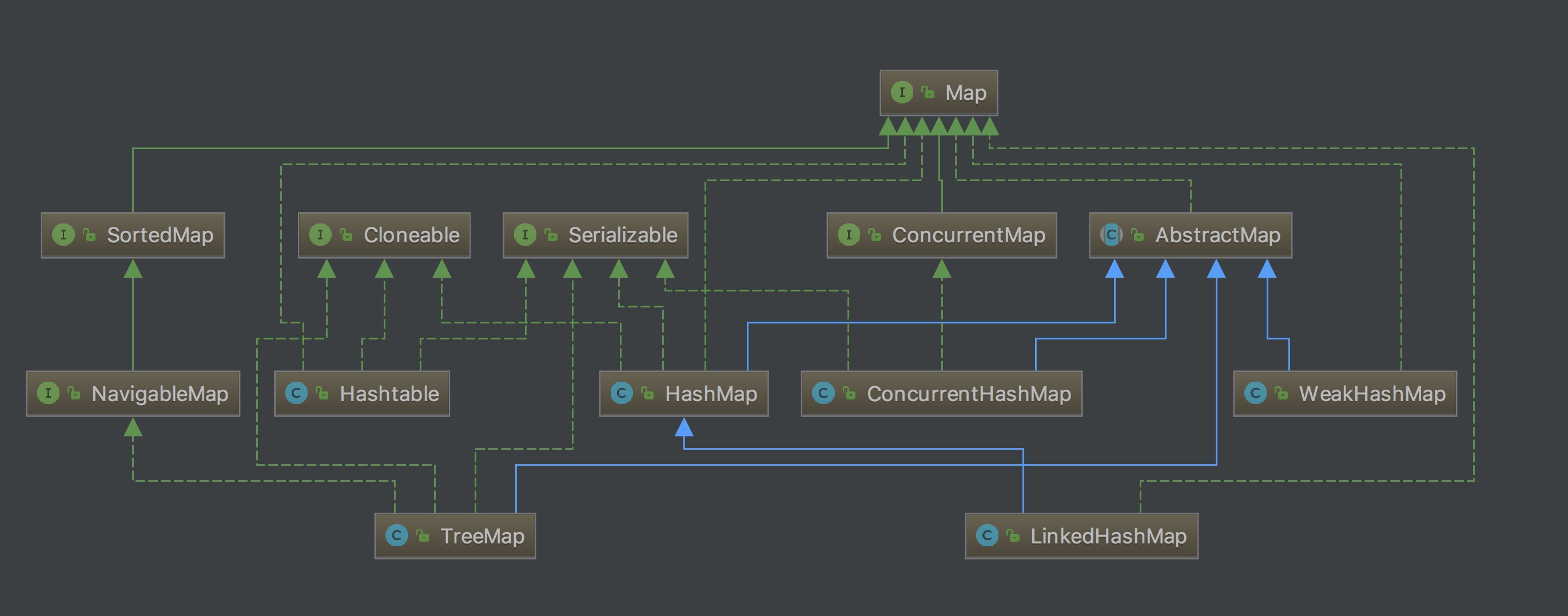

接下来说说 HashMap 和 ConcurrentHashMap
HashMap:
默认容量为16, 负载因子是0.75 均可修改
容量: 就是哈希桶的容量, 所谓哈希桶就是内部的 Entry<K,V>[] table, 容量就是它的容量.我们 put 的 key 和 value, 其实就是放在不同的哈希桶中的.
负载因子: 就是这个HashMap大概可以装到多满, 就是装的紧凑不紧凑 (后面会说到, HashMap 的 put Object 的时候, 不是挨着存放的). 0.75比较均衡, 高了容量利用重复, 但查询效率下降, 低了效率高, 空间利用不足. 我们很像让 hashmap 的每个桶装 1 个值, 但是效率就低, 如果所有值都放在1个桶里效率肯定高, 但空间利用低了. 当存数据个数大于 容量 * 负载因子, 就该扩容了.
内部结构大概长这样, 核心 Hash 桶就是 Entry<K,V>[] table:
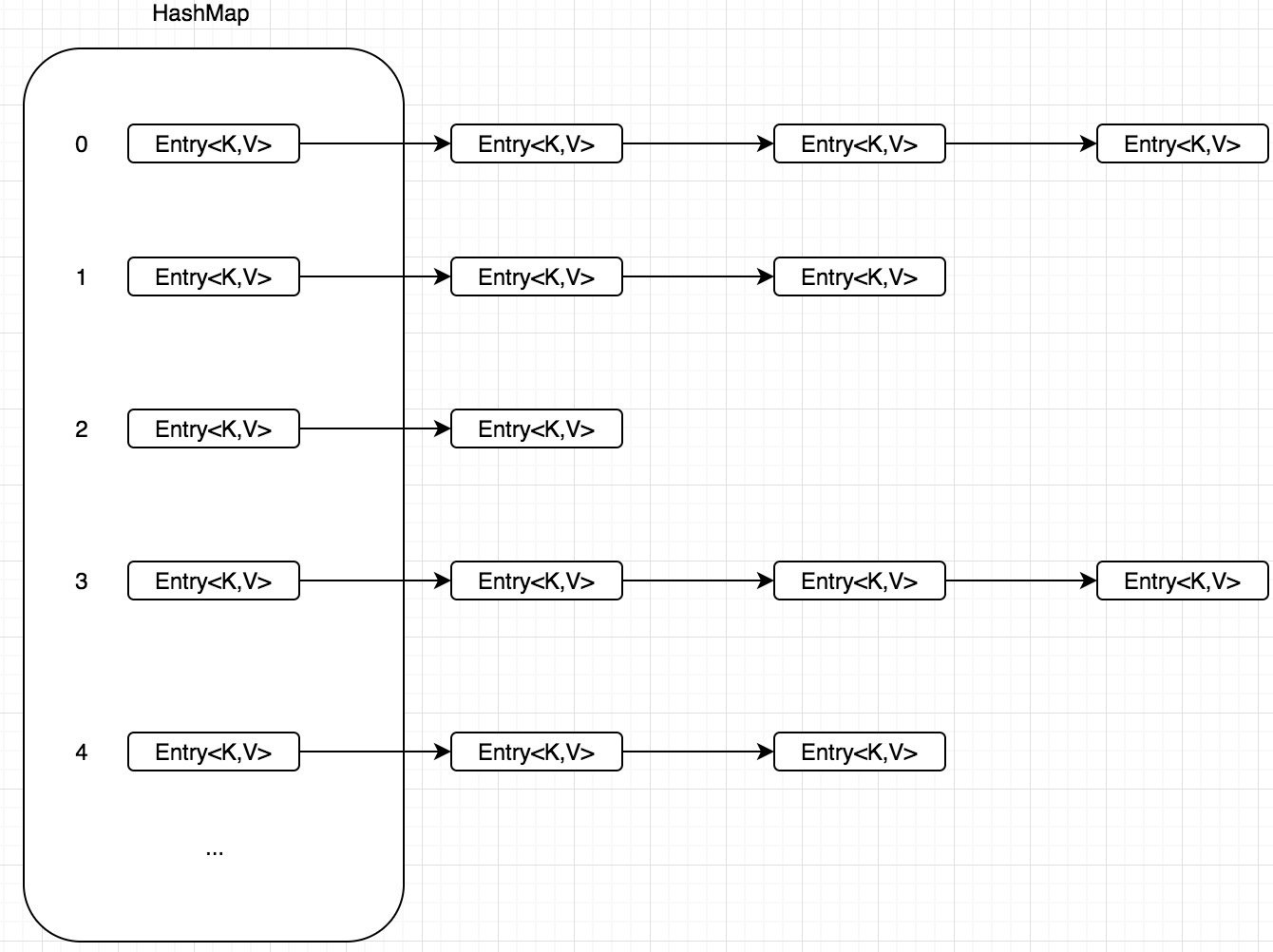
它的每一行都是一个链表, (Java 8 引入了红黑树, 当大小超过默认值大小 8 的时候, 将用红黑树替换链表, 加快查询速度)
HashMap 存放的时候可以用 Null 值, 直接返回 hashcode 为0, 并存在顶部. 重新插入 null 会被覆盖.
存入的时候会计算 key 的 hashcode, 再通过高位运算取模决定存放的位置, 当计算的 hashcode 值一样的时候, 就会发生 hash 碰撞, 这时候就放在一个桶里.
另一个就是扩容问题, 当容量超过出示容量的时候, 就会发生扩容, 扩大为原来的2倍. 这时候要重新计算 hash 值, 重新分布已有的数据, 比较费时. 扩容机制这里不谈, 又是一篇大论.
HashMap 是线程不安全的, 所谓不安全即对所有线程都可以获取并修改内容, 那么2个线程同时修改的化, 必定会造成数据不一致. 如果发生在 HashMap 扩容的时候, hashcode 重新计算, 可能造成死循环等问题. Java 5 以后引入了 ConcurrentHashMap 来解决问题. 当然你可以使用 HashTable, 它也是安全的, 不过它比较粗暴, 直接使用 synchronized 加锁.
ConcurrentHashMap:
引入了分段锁, 所谓的分段, 就是有很多的segment区, 一个segment 区包含了多个 HashEntry<K,V>, 并且提供完整的存取操作. 这样一来, 不同segment 区并发的时候, 就不会互相影响. 同一个segment区操作才会有锁竞争. 效率比 HashTable 提高很多.
另外它的锁用的是 ReentrantLock 锁, 并且用上了增强同步语意的 volatile 关键字. 这样保证多线程的可见性, 减少资源竞争.
ArrayList 和 LinkedList:
ArrayList 是动态数组的数据结构,LinkedList 是链表的数据结构。 也就是说 对于随机访问get和set,ArrayList优于LinkedList,因为LinkedList要移动指针。 对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
深浅克隆
浅克隆
Object o1 = new Object();
Object o2 = o1;
深克隆
Object o1 = new Object();
Object o2 = (Object)o1.clone();
注意: Object 必须实现 clone 方法, 因为默认的是 protected 作用域的, 此外必须调用 super.clone() 才能开辟新的堆空间
list 迭代器
for index 循环如果循环有重复执行 list.size()会导致结果错误, 循环中 add 会无限循环, remove 会减少循环次数
for each 或者 iterator 实现了次数验证的快速试错功能, 循环中 list.add() / list.remove() 会报 currentModifyException 错误, 只能 iterator.remove()
线程同步与并发
线程的可见性:
Java 的 JVM 内存对线程而言分为主内存和工作区内存, 也就是线程自己的内存. 每个单独的线程之间的数据是相互独立不可见的.
如果一个线程要操作主内存中的值, 是先从主内存中 copy 一份到工作区内存中, 操作完成后再同步到主内存中, 让其他线程可以继续操作.
线程结束后, 会将所有变量写回主内存, 但volatile修饰的变量会立刻写回. 另外线程释放锁也会将变量写回主内存, 得到相同锁的线程会得到最新的变量值.
原子性:
操作一个变量时, 从读取到操作再到放回都只有一个线程操作, 其他线程不能干预, 这样的操作叫原子性.
指令重排序:
计算机指令会对代码进行优化和重新排序. 比如
一个线程:
int i=0;int j=0;
i++;
j++;
另一个线程:
if(j == 1) {
System.out.println(i);
}
第二个线程感觉打印一定是 1, 因为 j 在 i 之后自加了. 但结果可能不是.
计算机帮你指令重排序后, 可能会先执行 j++, 所以你可能得到的结果是 0;
volatile 修饰的变量可以防止指令重排序.
锁:
公平锁和非公平锁: 公平即线程获取锁是有规则有序的, 非公平即线程竞争锁是随机的. 非公平锁可能导致线程一直等待. 公平锁可以用new ReentrantLock(true)实现.
自旋锁: 线程其实每次获取锁都要物理机帮助实现, 在和物理机切换状态的时候会花费额外开销. 自旋锁就是线程可以等待其他线程即将用完锁的时候, 接着拿下来继续用, 不再返回到物理机线程的机制. 这样减少了切换开销. 自旋是在轻量级锁中使用的,在重量级锁中,线程不使用自旋.
锁消除: 简单说就是你的代码写了一些方法加了锁, 但是编译的时候发现这段代码压根儿就是某个线程私有的, 资源是不可能被其他线程占用的, 就会把锁消除掉. 比如StringBuffer 的 append 方法其实是有锁的, 但是如果 操作对象被限制在一个方法内部, 那么锁就会被消除.
锁粗化: 同样, 如果虚拟机检查到一个对象多次反复的加锁操作, 那么就会把锁的范围扩大来提高性能.
重入锁( 递归锁 ): 当外层函数获取到一个锁之后, 继续往下或者继续调用的内部函数任然可以获取到这个锁, 就是重入锁. 典型的就是 ReentrantLock 和synchronized , 这样可以避免死锁.
偏向锁: 就是会优先选择第一次获得锁的线程, 这样会避免同步带来的消耗, 因为同一个线程不用担心同步问题.
悲观锁/乐观锁: 就是一个假设而已, 如果你觉得发生并发冲突, 那么你就撤销一切违规的操作. 这就是悲观锁. 如果你觉得不会发送并发冲突, 那么你只需要最后验证一下数据是否正确即可, 就是乐观锁.
读写锁: 就是可以多个线程读, 但是只能有一个线程写的锁, 比如 ReentrantReadWriteLock
互斥锁: 就是最多一个线程持有的锁.
semaphore: 信号量控制可以持有多少个执行凭证, 通过获取凭证/释放凭证达到控制线程访问数量. synchronized 的凭证数量为1, 即为互斥锁. semaphore(int, boolean) 分别定义了数量, 和是否公平锁.
线程池:
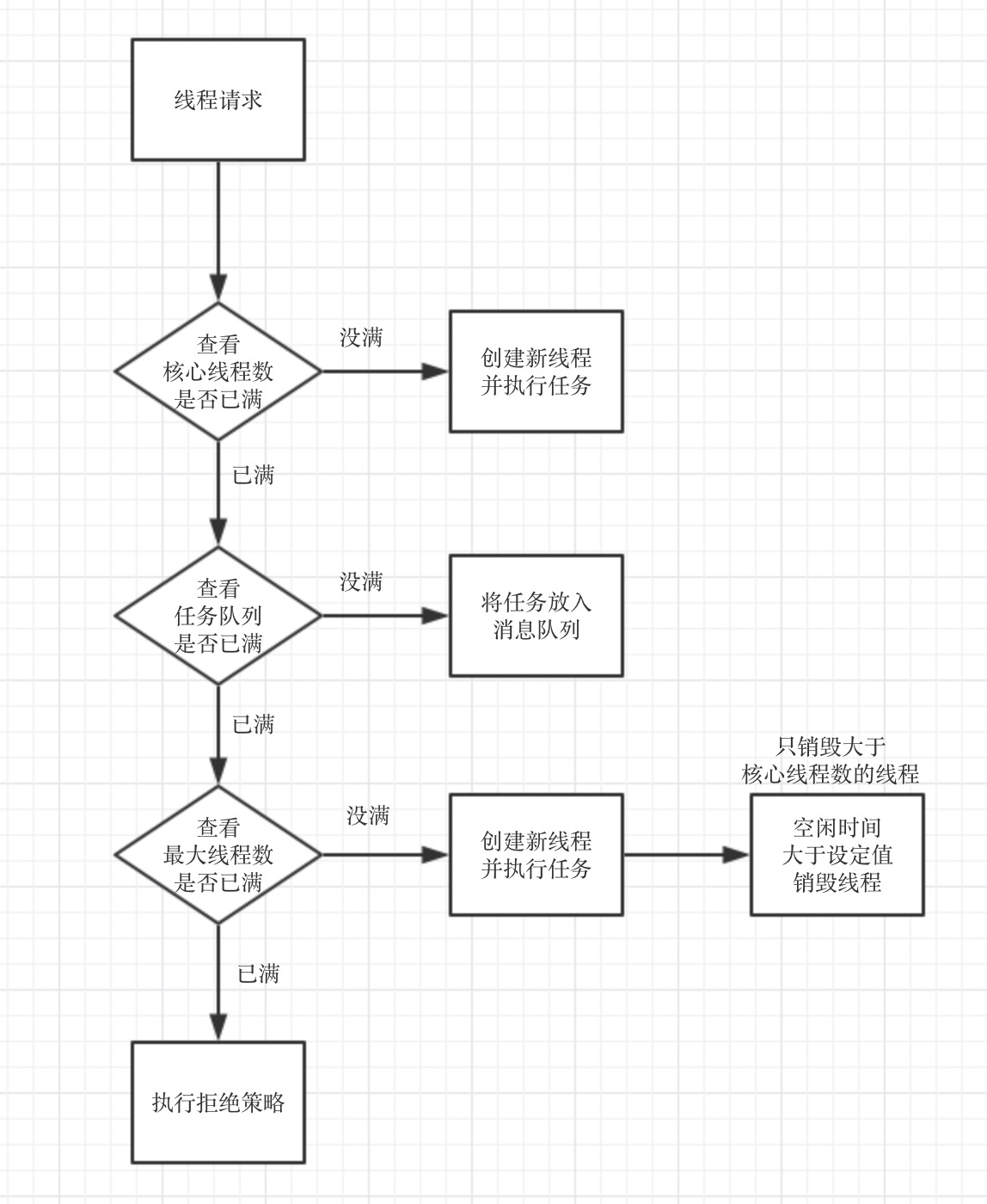
Java 提供了 ThreadPoolExecutor 类来实现线程池, 它的构造函数提供了如下配置参数:
corePoolSize: 核心池大小, 除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法, 否则初始化不会创建任何线程, 直到有任务到来. 当任务大于 corePoolSize 大小后, 将会把任务放到缓存队列.
maximumPoolSize: 最多能创建的线程数
keepAliveTime: 当线程数大于 corePoolSize 时, 线程空闲多久时间会终止.
workQueue: 选择哪种队列来存储等待的线程
handler: 拒绝处理任务时采取的策略
同时 Executors提供了一系列工厂方法用于创先线程池:
public static ExecutorService newFixedThreadPool(int nThreads)
创建固定数目线程的线程池。
public static ExecutorService newCachedThreadPool()
创建一个可缓存的线程池,调用execute将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线 程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。
public static ExecutorService newSingleThreadExecutor()
创建一个单线程化的Executor。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
这四种方法都是用的Executors中的ThreadFactory建立的线程
线程池生产和销毁机制
线程之间的协作:
CountDownLatch: 多个子线程同时工作, 完成之后使用countDown()标记完成, 主线程则使用await() 方法等待. 直到所有线程都完成后, 主线程继续执行.
CyclicBarrier: 预设的所有线程都跑到一个固定点调用 await() 方法的时候, 所有 await()的线程再一起继续执行.
Phaser: 所有任务线程都分为很多个步奏, 当到达一个步奏点的时候调用 await() 等待, 所有线程都完成一个步奏后同步, 再继续下一个步奏. CyclicBarrier 其实就是2个步奏.
NIO
和传统的阻塞式 BIO 相对的, 就是非阻塞式 NIO.
阻塞: 当线程执行 IO 的时候, 读和写都是阻塞的, 也就是说线程这个时候不能干任何其他事了. 必须等待完成.
NIO 引入了缓冲区 Buffer, 通过 java 内置 API, 可以对 buffer 做很多操作和配置.
NIO 引入了 channel, 一个 Channel 可以是单向的, 即只能读或者写, 也可以是双向的, 即可读也可以写. 一个线程可以管理多个 channel达到非阻塞的效果.
NIO 引入了 Selector, 管理着多个可供选择的 channel.
运用 NIO 常见的框架就是 Mina Netty 这种套接字服务框架.
设计模式
单例模式: 整个程序保证只有一个实例. 实现方式有懒饿汉式, 双重验证式, 静态内部类式, 枚举单例式等
工厂模式: 一个 factory 里获取所要的实例, 保证获取的实例都是单一的.
命令模式: 实现只有一个方法的接口, 即实现不同的命令, 将实现的命令类传给 executor 执行
装饰者模式: 不断封装一个方法, 使得功能更加强大.
代理模式: 类所有的方法, 都是交给内部另外一个代理类去处理
监听者/观察者模式: 被监听的类拥有所有监听者, 一旦变化, 通知所有的监听者.
Nullable 模式: 一个类如果是 Null 的, 返回一个具有一个 Null 特性的类, 避免 Nullable. 比如 Optional 会提供一个方法, isNull 等
策略模式: 一个抽象类或方法, 下面有不同的实现方式, 代码中根据不同情况, 选择不同的实现类处理.
Builder 模式: 内部有一个 builder 的构造器, 不断为主累构造必要的属性, 最后生成主类.
适配器模式: 一个接口有很多实现方法, 有时候我们并不想一一实现, 就会写一个抽象类, 实现大部分不需要的方法, 这个就是适配器. 就可以为更多不同的功能服务了.
还有很多, 不再一一介绍…
缓存:
缓存穿透: 查一个一定不存在的值, 就会每次绕过缓存去查数据库. 常见的解决方案: 缓存所有存在的 key, 不存在的不再查询数据库. 另外就是查询不存在这个结果也缓存起来. 设置好过期时间即可.
缓存雪崩: 设好的缓存在同一时间失效, 这个时间段数据库压力将变大甚至崩掉. 常见解决方案: 单线程存缓存, 保证失效时间不大多重复. 另外就是设计失效时间上加上随机值. 尽可能不同时失效.
缓存击穿: 某个值失效时, 大量请求这个 key 的线程过来, 导致查询 DB 负载过大. 解决方案: 查询缓存没有时, 加上锁, 单线程去查 DB 再缓存起来. 另外就是缓存设计为 永不过期, 然后用另外的线程去定时更新缓存.
缓存预热: 服务器刚上的时候, 未开通公网访问的时候, 内部建立任务跑一遍缓存, 达到缓存预热的效果, 避免新开服务器, 缓存为空的情况.
Java 8, Java 9 新特性
java8
lamda 函数式编程的引入
利用 Java7 的 ForkJoin 并发框架实现并行流的操作
Interface 接口的更改, 可以有 default 方法, 静态方法等等
双冒号的方法引用
重复注解的引入
API 的优化, 比如 Map 的 putIfAbsent, Optional 的引入等
时间类 Time 的优化
类型推断增强, 编译器的改进, JVM 优化等等…
java9
参看另外一篇我的文章: Java 9 New Features
JVM
(Java 虚拟机的配置参数这里不做介绍, 感兴趣的可以自行查询)
运行时数据区:
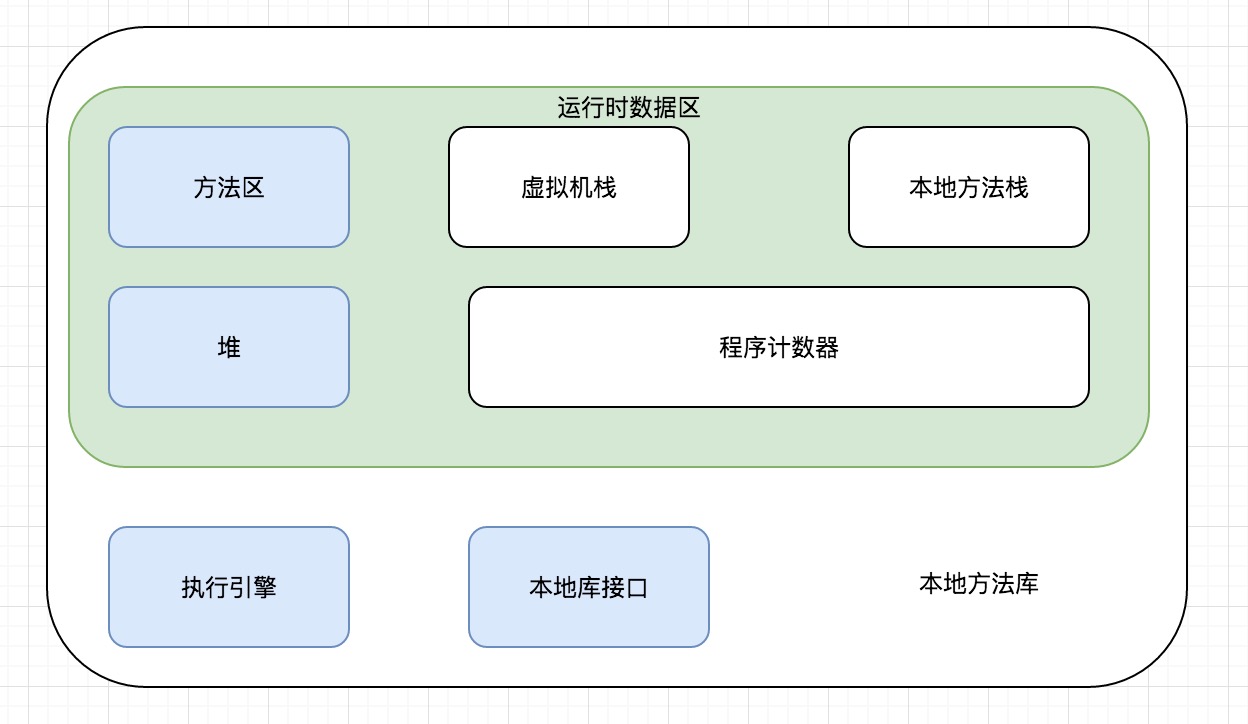
除了程序计数器以外, 其他区域均可发生 OutOfMemory 异常.
线程请求的栈深度大于允许的最大深度, 抛出 StackOverFlow 异常, 虚拟机扩展栈时无法申请到足够内存抛出 OutOfMemeory 异常.
其中堆, 又划分为 新生代和老年代. 这里是线程共享的. 当然像常量, 静态变量, 类, 代码… 这些被划分在永久代里.
Java 的 NIO 开启 DirectByteBuffer可以直接访问和操作物理机内存.
当一个 Object 被 new 的时候. 先检查是否为常量以及是否被加载过. 紧接着确定大小后为其划分内存, 在堆中划分内存的时候, 看分配算法, 如果用的 GC 是压缩整理器, 就分配规则的内存(Bump the pointer), 如果用像 CMS 标记的 GC 器, 就用记录列表法(FreeList). 分配内存也要考虑竞争关系. CAS 重试或者加锁线程安全等. 最后设置头信息, 初始化方法.
GC算法和收集器
引用计数器算法: 被用一次, 标记1, 没有引用等待清理, 但无法解决互相引用问题
可达性分析: 从 ROOT 往下筛选, 看是否能达到 object,可达标记一次, 第一次 GC做且只做一次筛选操作, 即 finalize(). 第二次 GC 清除
GC常见算法:
- 标记清除法
- 复制算法, 新生代常用
- 标记整理算法
Full GC 会执行 stoptheworld 操作, 所有线程必须跑到设定的安全区挂起等待. 再轮训是否 GC 完毕.
常用垃圾收集器
新生代:
Serial 收集器
ParNew 收集器, 常配合 CMS
Parallel Scavenge 可以自适应调节
老年代:
Serial Old
Parallel Old
CMS
重点讲一下 CMS 的垃圾清理步奏:
- 初始化标记
- 并发标记
- 重新标记
- 并发删除
JVM 调优
Jps
Jstat
jInfo
jmap
jhat
jstack
JVM 调优非常复杂, 需要结合各种工具, 分析 JVM 日志, 才能做出相应的调整, 有时候也可以利用这些工具分析出程序的不足.
JVM类加载机制
说一个双亲委派机制吧, JVM 为了允许我们自己定义类加载器, 实现了双亲委派机制;
启动类加载器 Bootstrap classloader
扩展类加载器 ExtentionClassLoader
应用程序类加载器 ApplicationClassLoader
然后是各种不同的用户自定义的类加载器. 加载一个类的时候, 会先查看是否加载过这个类, 如果没有, 就会先调用父类加载器加载, 如果父类没有, 就调用启动类加载器加载, 如果还没有才会调用我们自己的类加载器. 就是说都会从顶层找一遍, 再往下.
我们知道不同的类加载器加载出来的来是不同的, 也就是 equals 的时候为 false. 双亲委派的好处就是尽可能保证类加载出来都是出自同一个类加载器, 不会导致加载出来的类不一样的问题.
( 哈哈哈, 赶着睡觉…后面一些写的很草率, 不是很懂的小伙伴自己再百度吧. 其实最重要的不是背住这些知识点去面试, 而是真正理解, 去项目上实践, 成为自己的才最重要 🙂 )

谢谢分享